


Help Situation identification in drone surveillance using action recognition
Help Situation identification in drone surveillance using action recognition
Introduction:
Nowadays Natural disasters kill on average 60,000 people per year, globally.
disasters were responsible for 0.1% of deaths over the past decade. This was highly variable, ranging from 0.01% to 0.4%. of global deaths most of these are due to the delay in identification of the survivors with human force so in order to overcome this problem drone surveillance is the one of the modern alternative for this problem.Moreover the previous approaches like sending air force for identification is the expensive alternative .So with the drone surveillance we can get an entire view of the disaster location and also identify the survivors more efficiently and the cost of drones is less when compared to the human and air force.so with the help of another advanced technology called deep learning we have created models which can identify the survivors based on their actions and lets us know where the survivors are stuck
Activity recognition is consistently an indispensable assignment as it can likewise diminish crime percentage and furthermore helps in the deplorable circumstances .There were numerous methodologies for doing the activity recognition and there's a ton progress in increasing the accuracy of the model from the basic model from extracting low level features from video caught from the reconnaissance cameras which can't cover the general view and passing them to classifiers like SVM(support Vector Machine),Naive Bayes,K-Nearest Neighbor and other classifiers to extracting every pixel from frames in videos that are captured from the drones which covers the whole view and passing them to the pre trained models like Imagenet,Resnet50,Vgg16
Out of all the models for action recognition , the basic step in every action recognition model is the extraction of frames from every video and resizing all the frames to a equal size and passing them to the models ,creating objects for the model and loading weights to the model and the final step is passing data for prediction where the model returns the class or label which is most similar to the input data of prediction
After an study of a great deal of models we built the 3D-CNN(Convolutional Neural Network),CNN and LSTM(Convolutional Neural Network and Long Short Term Memory) and the TSN(Temporal Segment Network) and furthermore trained the pretrained models like Resnet50,Resnet152,VGG19 with our dataset
Project Description:
The aim of our project is to identify the survivors through their actions or in any state during the disasters and reduce the number of deaths in disasters
Dataset used:
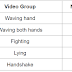
The dataset that we have created contains videos that have been recorded at a height of about 10-15 meters with actions such as 'Waving a hand,' 'Waving both hands,' 'Fighting,' 'Lying,' 'Handshake.These videos have been recorded at different times of day and from different angles to train model properly.For further experiments, "DCSASS" dataset and "UCF rooftop" dataset were merged with the recorded dataset in order to obtain larger amounts of data and train the models with that data set.
In the dataset every class consists of number of videos ranging from 74-86 to make the data balanced.

Data Preprocessing:
As we cannot directly pass a video to any model so we have to extract each frame from every video and pass it to the model and we split the data into 2 parts that is training data and the testing data first we train the model with the training data and then test the model with the testing data. and run the model with small changes in the parameters until we get a satisfied outcome.
Models:
There are three models which we have created ,trained and tested them for the action recognition and the three models are:
1. 3D-CNN(Three dimensional Convolutional Neural Network)
2. CNN and LSTM(Convolutional Neural Network and Long Short Term Network)
3. TSN(Temporal Segment Network)
3D-CNN:
We know that the 1D-CNN model is usually used for statistic knowledge and therefore the 2D-CNN model has the best accuracy in image classification and once it involves the 3D-CNN the dimension is for the statistic since videos area unit temporal knowledge. The output for the 3D-CNN is four dimensional.The 3D convolution is achieved by convolving a 3D kernel to the cube shaped by stacking multiple contiguous frames along.By this construction, the feature map within the convolution layer is connected to multiple contiguous frames .
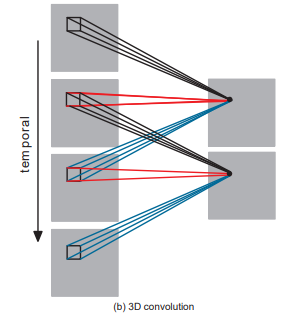
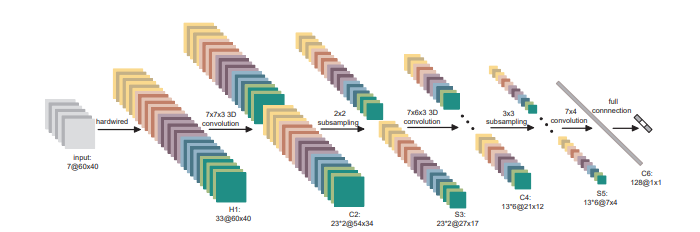
for the 3D-CNN model; we've resized each frame to 32,32,32 with depth thirty two and so we tend to passed the info to Conv3d layer , maxpooling3d ,flatten,dense,batch_normalization,dropout with activation functions and extracted the utmost options from the input file and born-again it into the dimensions of labels or categories the dataset we've taken consists of five categories
 |
| layers of 3dcnn model |
the 3dcnn architecture for human action action recognition
Graphs:
Accuracy of 3dcnn model:

loss of 3dcnn model

2D-CNN and LSTM Model:
2D-CNN area unit familiar for his or her accuracy within the image classification and LSTM area unit the most effective perennial neural network and therefore the combination of those ends up in another model with a quite smart accuracy and might be used for action recognition. Long Short Term Memory networks area unit a special quite RNN, capable of learning semipermanent dependencies. LSTMs area unit expressly designed to avoid the semipermanent dependency drawback. basic cognitive process data for long periods of some time is much of their default behavior.All perennial neural networks have the form of a sequence of continuation modules of neural networks. In commonplace RNNs, this continuation module can have a really easy structure, like one tanh layer.The first step in LSTM is to make a decision what data we’re planning to throw faraway from the cell state.This call is created by a sigmoid layer and outputs range|variety} between zero and one for every number within the cell state .The next step is to create a call what new data we’re reaching to store among the cell state. This has 2 components. First, a sigmoid layer decides that values we’ll update. Next, a tanh layer creates a vector of latest candidate values that might be else to the state. within the next step, we’ll mix these 2 to form associate degree update to the state.Then time to update the previous cell state.Using LSTM layer reduces the matter of overfitting

Each 2D CNN processes the convolution computing for the input multichannel 2D image and extracts features on its plane. Each convolutional kernel is convolved across the width and height of 2D input volumes from the previous layer, computing the scalar product between the kernel and therefore the input. The results of all input volumes are summed to reach the results of this kernel, producing a 2-dimensional activation map for every kernel.
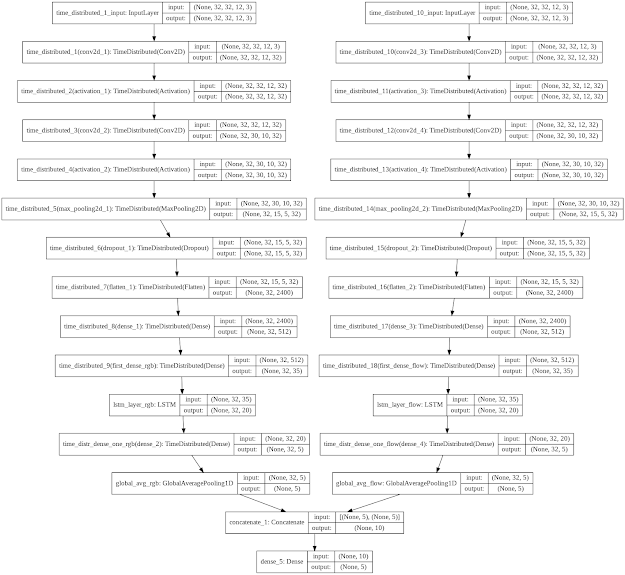






In this model we have used the time distributed layer for the Conv2d to make its function almost similar to 3dcnn .For this model we use every layer in combination with time distributed layer and the layers used in this model are Conv2D, Maxpooling2D,dense flatten,dropout in combination with the time distributed layer and global averagepooling1D and the concatenate layers are used to join the 2 CNN and LSTM models and the dense layer is used to convert to the labels or classes size

Graphs:
Accuracy for 2D-CNN and LSTM model:

Loss for 2D-CNN and LSTM model:

TSN(temporal Segment network):
Temporal section Network is another approach for action recognition. In this, the video input is born-again into many segments/snippets that's components of the video. This model consists of spatial Convnet and temporal Convnet. Instead of performing on single frames or frame stacks, the time-segment networks run a sequence of short snippets that area unit sparsely sampled from the whole video. each of the snippets during this sequence can

Formally, given a video V , we tend to divide it into K segments of equal durations. Then, the temporal section network models a sequence of snippets as follows:
TSN(T1, T2, · · · , TK) = H(G(F(T1;W), F(T2;W), · · · , F(TK;W)))
Here (T1, T2, · · · , TK) may be a sequence of snippets. every snipping Tk is indiscriminately sampled from its corresponding section Sk. F(Tk;W) is that the operate representing a ConvNet with parameters W that operates on the short snipping Tk and produces category scores for all the categories. The Segmental agreement operates G combines the outputs from multiple short snippets to get an agreement on the category hypothesis between them. supported this agreement, the prediction operates H predicts the likelihood of every action category for the whole video. this can be wherever we elect the wide used Softmax to operate for H. Combining with customary categorical cross-entropy loss, the ultimate loss operate relating to the segmental agreement G = G(F(T1;W), F(T2;W), · · · , F(TK;W)) is made as
is 

where C is the number of action classes and yi the truth label concerning class i.
This time-segment network is also separated or a minimum of has subgradients, betting on the preference of g. this enables North American countries to use multiple snippets to optimize model W parameters besides customary back-propagation algorithms.
Graphs:
Accuracy of TSN model:

Loss of TSN model:

ACCURACIES OBTAINED AFTER TRAINING MODEL WITH DIFFERENT METHODS:
3D-CNN:87%
2D CNN+LSTM:57%
TSN:75%
Result:
We have considered 80% of data as training data and 20% of data as test data and we compiled the model with Adam optimizer. Adam was utilized as the advancement calculation since it is far superior to calculations like AdaGrad and RMSProp. This is on the grounds that Adam consolidates the best of their properties to manage loud issues. The measurements utilized for assessment was exactness. We got the highest accuracy with the 3D-CNN model. We made a user interface and deployed the 3D-CNN model in the web using flask
Conclusion :
We have studied various models for the usage of activity recognition and out of those models we got the most elevated exactness for 3D-CNN
Future Scope:
- We can train the model on GPU's for more accuracy and deploy them in drones for identification of survivors in disastrous places
- We can also train the model with data with the"DSASS" dataset and can use it for crime detection which reduces the crime rate
- It reduces the human efforts and expenses required to find the survivors in disastrous places
Limitations:
- The atmospheric conditions in disastrous places is blurry foggy and hence dataset under such circumstances is not available
- The gap between the complete representation of human activities and the corresponding collection and annotation of data is still a challenging and unbridled problem.
No comments:
Post a Comment